S’il est relativement simple de transcrire un audio de quelques minutes où une personne parle, transcrire plusieurs heures d’échanges à plusieurs intervenants, avec des chevauchements de parole et des termes métier, est une tâche moins évidente. Surtout quand l’objectif est ensuite de produire un compte rendu fiable, où les interlocuteurs doivent être identifiés continuellement (la reconnaissance des interlocuteurs s'appelle la diarisation).
Dans cet article, nous allons voir pourquoi les transcriptions classiques ont leurs limites, et comment combiner différentes approches pour obtenir une transcription à la fois cohérente, précise et diarisée.
Pourquoi les transcriptions classiques peuvent échouer
Pour attaquer le problème de la transcription en général, deux familles de modèles existent :
Reconnaissance automatique de la parole (ASR) en continu
D’un côté, on a les systèmes d’ASR (Automatic Speech Recognition) continus, qui n'ont accès qu'à un contexte local de l'audio pour l'enregistrement, et se basent donc surtout sur des aspects phonétiques / à court terme. Ils ont des performances stables avec la longueur de l’enregistrement. Cela les rend aussi faillibles : certaines expressions phonétiquement proches peuvent être difficiles à discriminer sans informations sémantiques globales.
Ces systèmes peuvent tenir compte de façon précise de la temporalité de chaque mot, ce qui permet de synchroniser le texte avec l’audio, mais surtout de les coupler avec un modèle de diarisation, qui permet d’attribuer chaque prise de parole à un intervenant, de façon cohérente sur de longues durées. On peut ainsi attribuer un horodatage (timestamp) et une identité à toute prise de parole.
Une liste de mots clés peut éventuellement être fournie pour artificiellement augmenter la probabilité de certains mots, mais cela ne permet qu’une prise en compte limitée du contexte externe à l’enregistrement.
En résumé : performances moyennes à bonnes, mais indépendantes de la longueur de l’entrée, avec une diarisation fiable au long terme.
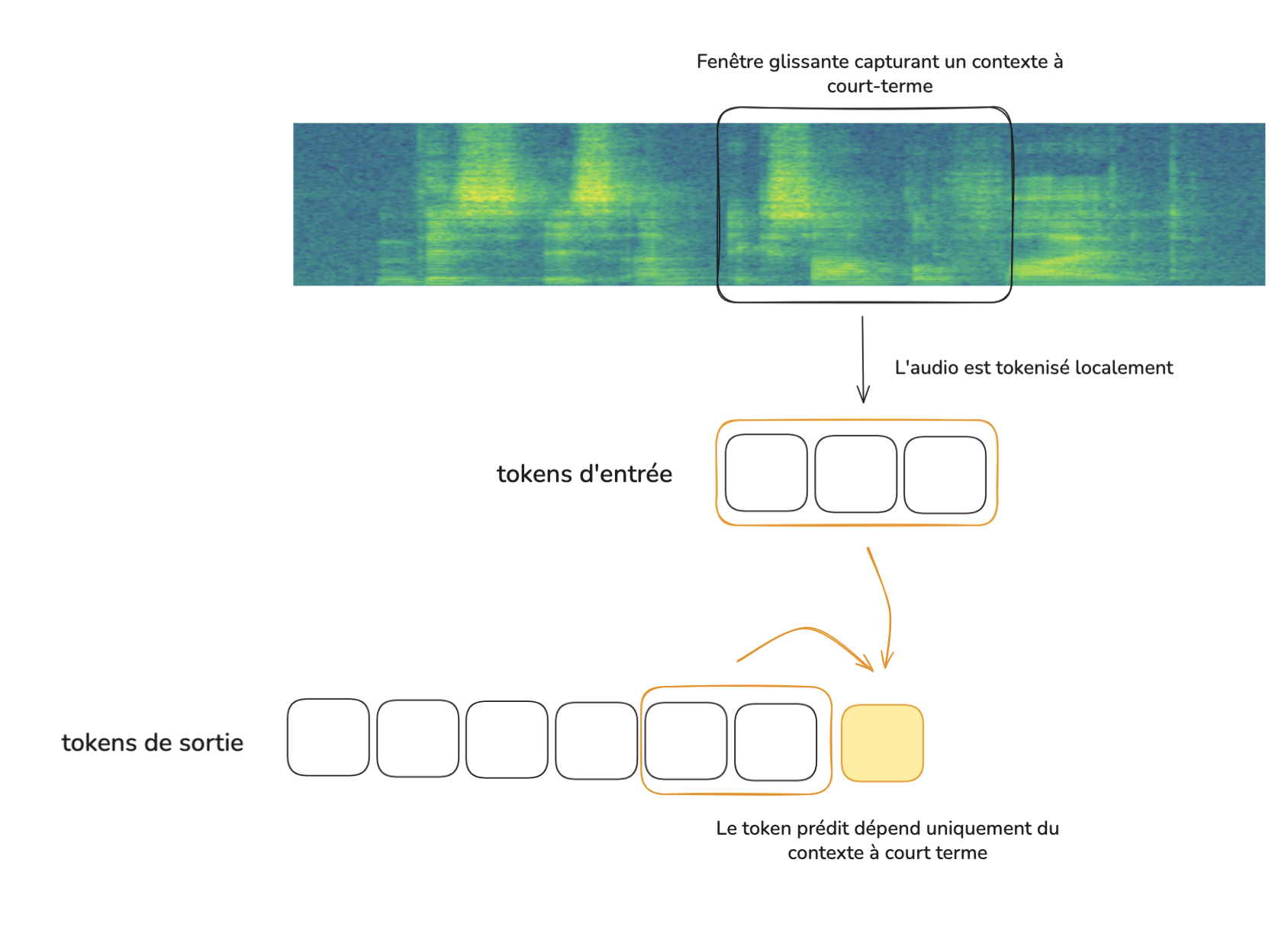
Schéma simplifié d'un modèle d'ASR continu
Grand modèle de langage multimodal (MLLM)
D’un autre côté, on a les LLMs multimodaux, qui prennent en compte l’intégralité du contexte pour transcrire chaque mot, et assurent donc une cohérence contextuelle à long terme.
Leurs fortes performances dans les tâches liée au langage assurent une compréhension fine de l’enregistrement, et évitent de nombreux contresens. Ils peuvent être enrichis d’informations annexes complètes, mais aussi effectuer de la diarisation de façon précise.
En revanche, leurs performances se dégradent avec la longueur de l’entrée :
Quand le contexte devient trop riche, les prédictions deviennent bruitées.
Certaines informations précises peuvent se perdre, la génération perd en qualité.
Le coût de l’inférence augmente avec la taille de l’entrée.
Ici, les interventions ne peuvent pas être horodatées de façon précise. Il est possible de demander des timestamps, mais il seront très souvent hallucinés par le modèle.
En bref : d’excellentes performances sur des contextes modérés, mais qui se dégradent et deviennent coûteux sur de longs enregistrements.
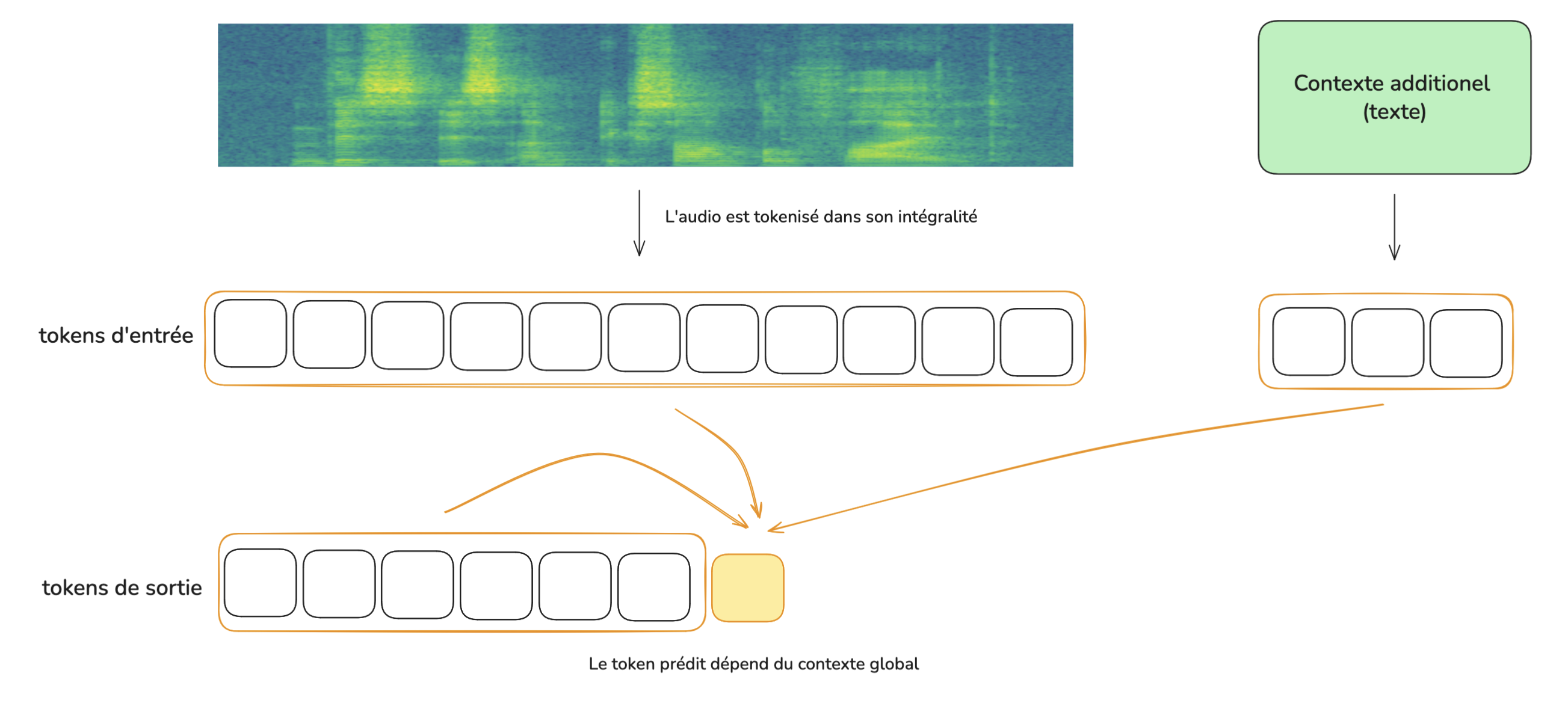
Schéma simplifié d'un MLLM dans le cadre d'une transcription
On peut noter que les systèmes d’ASR seuls ont souvent une bien meilleure latence que les LLMs multimodaux et sont donc souvent plus appropriés pour de la transcription en temps réel. Dans notre cas, la latence n’est pas un enjeu, donc ce critère n’est pas pris en compte.
Comment combiner le meilleur des deux mondes
Plutôt que de trouver un compromis entre les deux, on peut utiliser les deux systèmes simultanément.
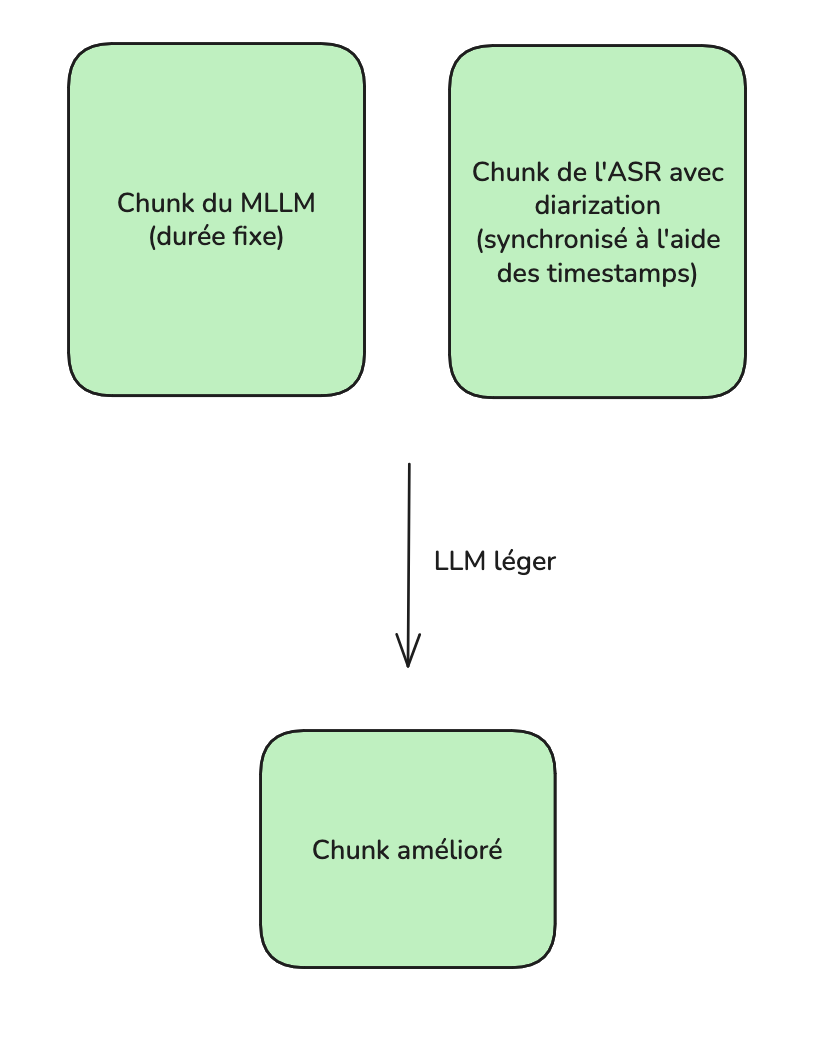
Étape 1 : Découpage en chunks pour le MLLM
Pour conserver des performances optimales du MLLM, on découpe l’enregistrement en chunks de taille fixe (10-15 minutes par exemple), avec chevauchement (overlap), chacun traité séparément, en injectant à chaque fois des informations contextuelles globales.
Ainsi, le modèle peut utiliser des informations contextuelles riches, mais sans que la longueur de l'entrée ne dégrade sa qualité. On lui demande de fournir une transcription diarisée de façon assez libre.
Limite : on perd le suivi des identités des intervenants au long terme, car les chunks sont traités indépendamment : impossible de savoir si l'intervenant n°2 du premier chunk est le même que l'intervenant n°2 du dernier chunk.
Étape 2 : Analyse complète via ASR continu + diarisation
Pour le système d’ASR continu avec diarisation, l’audio peut être analysé d’une traite. Le résultat aura la forme de segments, associés à un interlocuteur et à un indicateur temporel. Ces timestamps permettent de découper le résultat en chunks synchronisés avec ceux du MLLM.
Étape 3 : Fusion chunk par chunk
Ces chunks synchronisés sont ensuite fusionnés deux par deux avec un LLM léger et peu coûteux.
Fusion des chunks correspondant à une même portion de l’enregistrement :
Étape 4 : Fusion finale
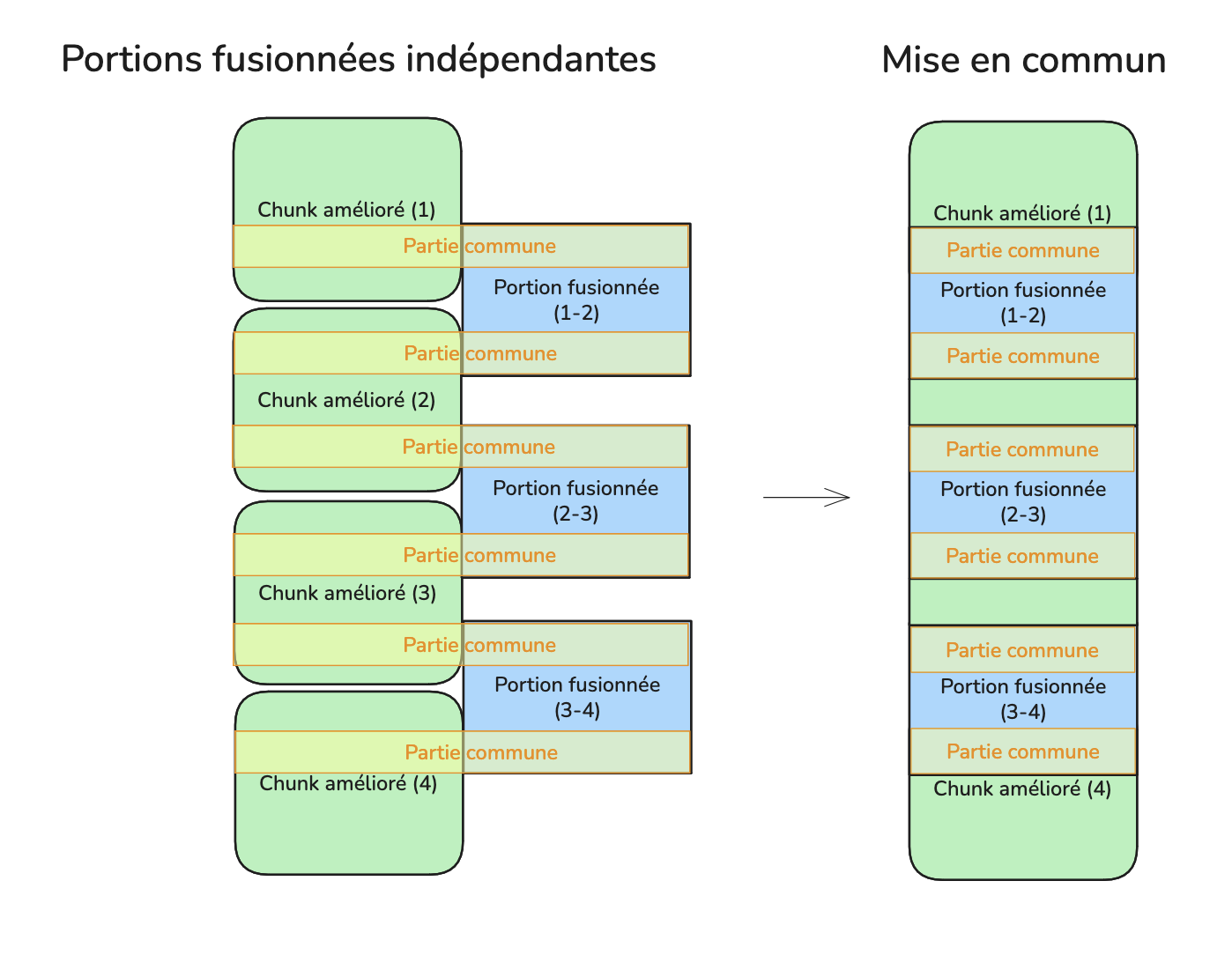
Enfin, tous ces chunks améliorés sont fusionnés pour produire une transcription unifiée.
Un LLM léger est utilisé à nouveau pour limiter la consommation de ressources.
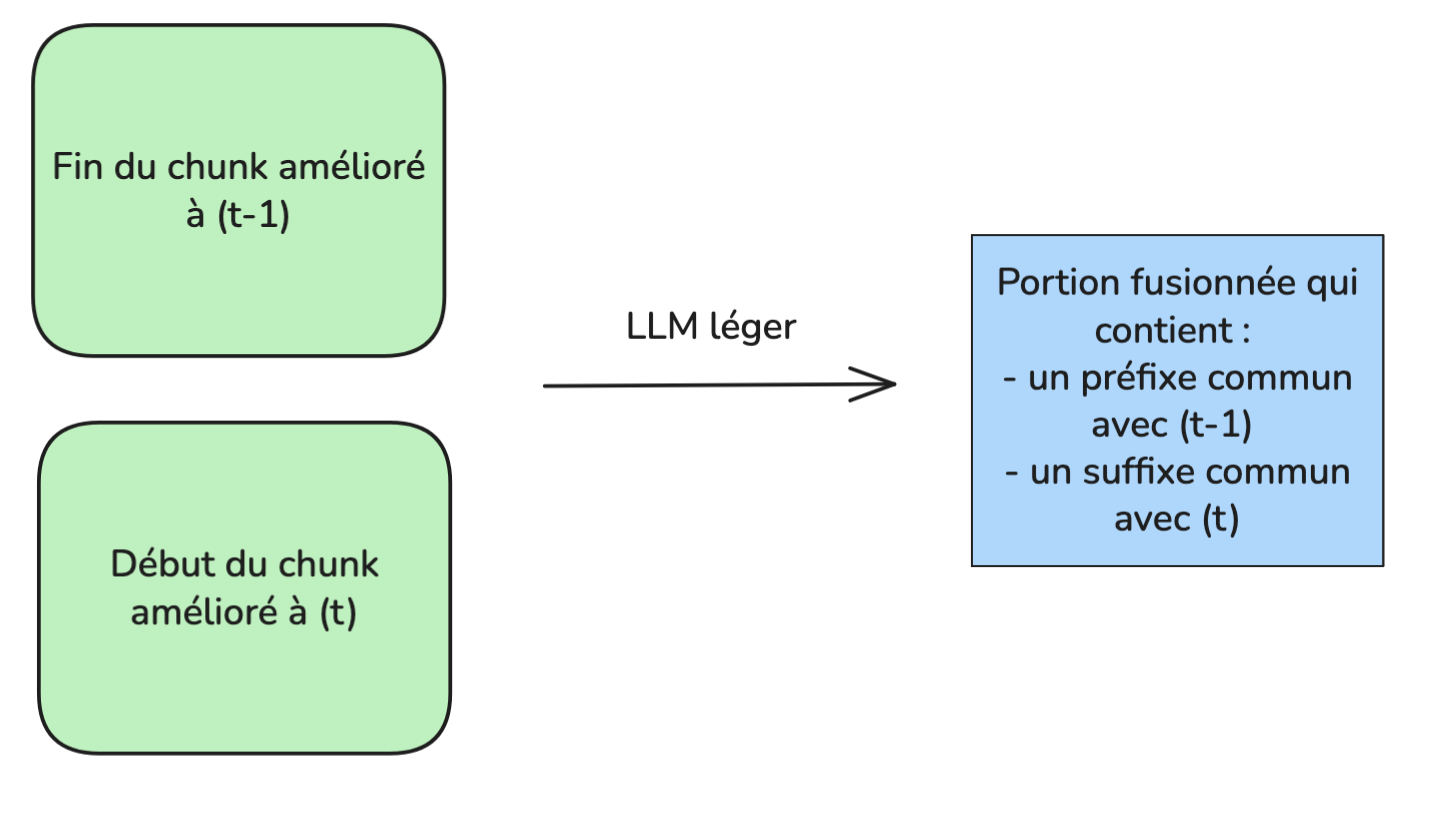
Les chunks adjacents sont fusionnés deux par deux, avec chevauchement pour faciliter les transitions.
Le modèle reçoit l’instruction de produire un texte unique ayant un préfixe commun avec le début du contexte précédent, et un suffixe commun avec la fin du contexte suivant.
Le chevauchement entre les chunks garantit qu’aucune information n’est perdue dans le processus
Résultat : une transcription fiable, cohérente, et diarisée sur toute la durée.
Fusion de deux chunks consécutifs, de façon à pouvoir fusionner l’ensemble des chunks facilement ensuite :
Fusion de l’ensemble des chunks :
Analyse des coûts
Les méthodes de transcription et de fusion sont indépendantes de la longueur de l’entrée, donc la qualité reste constante. Le coût est aussi linéaire en la longueur de l’entrée, ce qui rend le procédé viable pour des enregistrements de longueurs arbitrairement longues. Le coût du MLLM est dominant dans l’ensemble, le reste ajoutant environ 30-50%. D'un point de vue économique, on se situe autour de 0.50€ - 1€ par heure d'audio.
En termes de consommation de ressources, on est en deça d'un appel unique à un MLLM, (comme on pourrait le faire sur un chatbot) quand l'enregistrement dure plusieurs heures. En effet, les MLLMs (et les LLMs en général) ont un coût par token qui augmente avec la longueur de l'entrée ou de la sortie. En se reistreignant à des chunks de 10-15 minutes, la consommation par token reste modérée.
En pratique, certains providers pour la partie ASR + diarisation limitent les traitements à 4–6 heures d’audio, ce qui peut être une limite. Un système analogue peut être conçu manuellement à l'aide de la bibliothèque pyannote et d'un modèle local.
Métriques
Les différentes méthodes ont été comparées sur le dataset FLEURS fr (enregistrements courts avec un seul intervenant) pour mettre en évidence le transfert de qualité du MLLM à notre approche. Et sur le dataset SUMM-RE (réunions avec plusieurs intervenants), où le nombre d'erreurs a été compté en LLM-as-a-judge.
FLEURS - FR
| Mode | Raw WER |
|---|
| azure speech recognition (diarized) | 9.6% |
| gemini 3 flash | 3.1% |
| dual transcription (ours) | 3.1% |
SUMM-RE - FR
| Mode | semantic discrepancies (minor) | semantic discrepancies (major) | speaker attribution precision |
|---|
| azure speech recognition (diarized) | 12 | 2 | 86% |
| gemini 3 flash | 3 | 0 | |
| dual transcription (ours) | 2 | 0 | 88% |
Conclusion
La méthode décrite ici permet de transposer la qualité de transcription qu’on sait obtenir sur des audios courts, à des enregistrements arbitrairement longs. Cela s’accompagne d’une augmentation substantielle des coûts, mais qui est à relativiser avec le coût total du système, dont la transcription n’est qu’une étape. Ainsi, on évite de nombreuses erreurs qui seraient incorrigibles lors du passage de la transcription au compte rendu final.
Bonnes pratiques
Inclure un overlap entre chunks pour faciliter la fusion (environ 30s - 1 minute).
Utiliser des chunks suffisamment longs pour que le MLLM tire profit des informations contextuelles, mais suffisamment court pour ne pas dégrader ses performances (10-20 mins est un bon compromis).
Si possible, régler la température à une valeur proche de 0 dans le MLLM pour limiter le bruit
Un système plus simple que celui-là sera une meilleure option si le but est de transcrire des audios courts (quelques dizaines de minutes).