Les LLMs couplés à des systèmes OCR permettent aujourd'hui d'automatiser le traitement de documents PDF ou images : résumés, extraction de données structurées, alimentation de chatbots… Mais ces modèles hallucinent. Et pour des tâches critiques où l'erreur n'est pas tolérée, un humain doit vérifier chaque résultat.
Le problème : cette vérification est souvent aussi longue que de faire le travail soi-même. Face à un document de 50 pages, le vérificateur doit retrouver l'information pertinente avant même de pouvoir valider la réponse du LLM, un travail que le modèle a déjà fait de son côté, sans en laisser de trace exploitable.
La solution décrite ici repose sur un constat simple : le LLM sait où il a trouvé l'information, il suffit de lui demander de le montrer. En exploitant les métadonnées de localisation fournies par l'OCR, il est possible de surligner directement sur le document source le segment de texte qui justifie chaque élément de la réponse. C'est ce qu'on appelle une preuve visuelle.
Des preuves, oui mais à quel niveau ?
L'idée de fournir des preuves à l'utilisateur n'est pas nouvelle. Les chatbots connectés (ChatGPT, Perplexity, Grok…) affichent des liens cliquables vers leurs sources. Mais ces preuves restent de « haut niveau » : pour vérifier, il faut encore lire la source, ce qui peut être long.
Le moteur de recherche Google offre un meilleur modèle. Pour certaines requêtes, il ne se contente pas de lister des liens : il affiche l'extrait précis de la page qui contient la réponse, en surlignant le passage pertinent. C'est ce niveau de granularité que le système présenté ici transpose au traitement de documents par OCR + LLM.
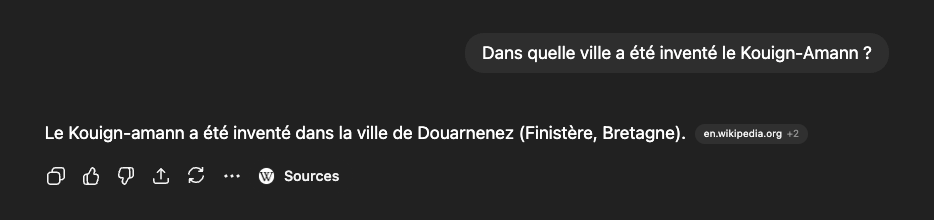
Exemple de preuve dans un chatbot connecté (ChatGPT)
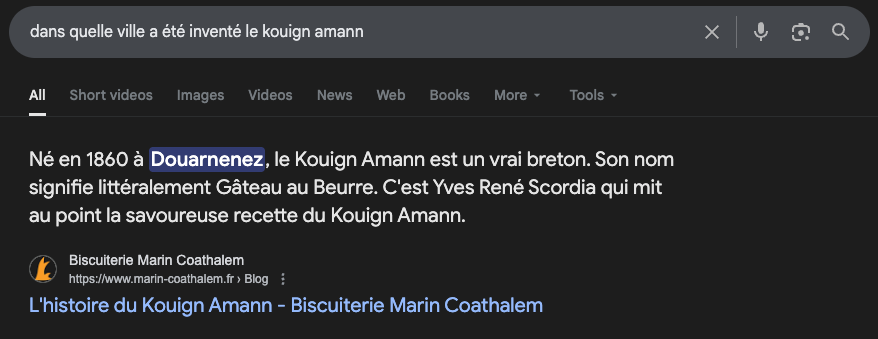
Exemple de preuve visuelle dans une recherche Google
L'expérience utilisateur : cliquer pour vérifier
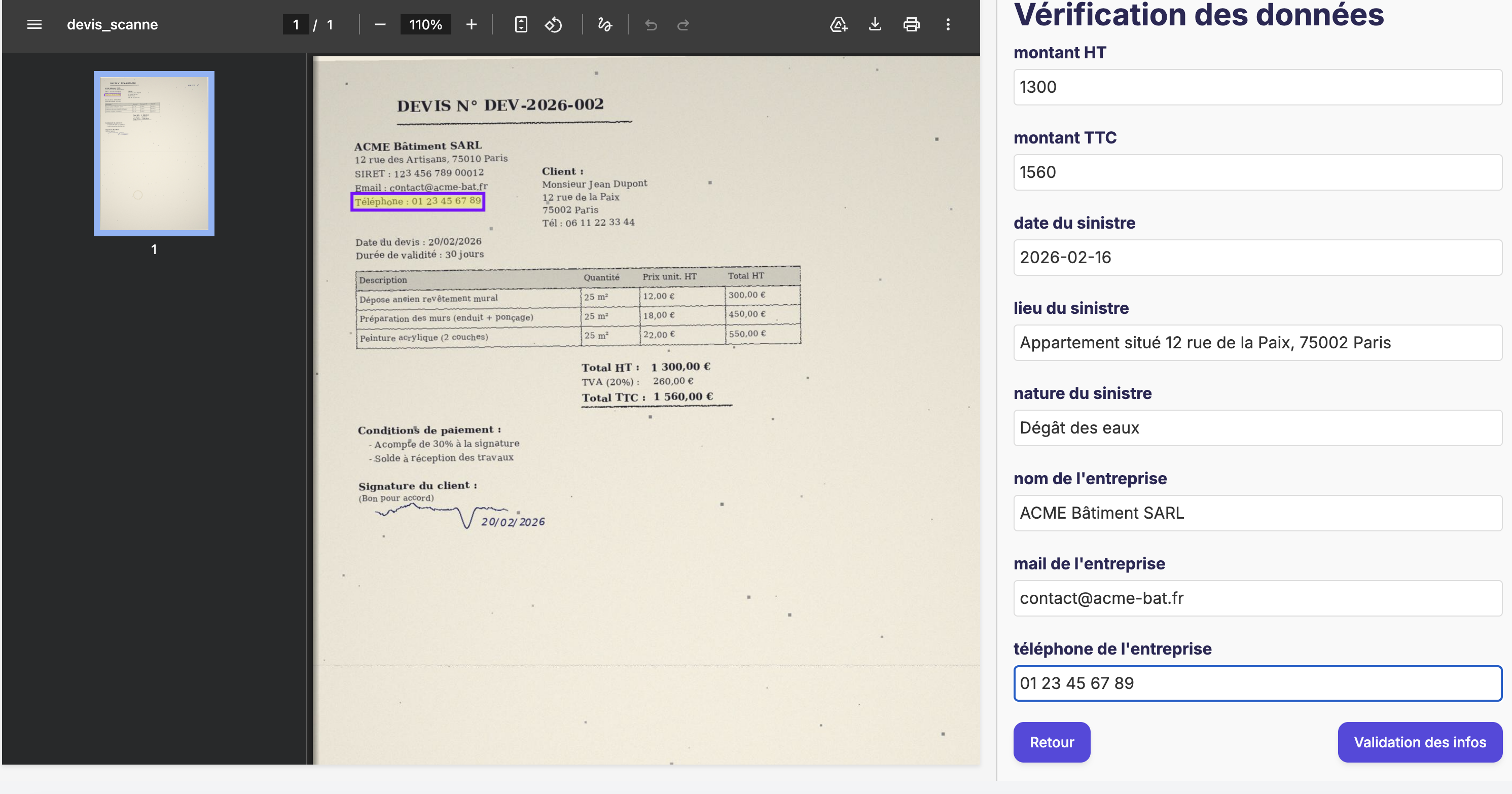
L'interface se divise en deux volets. À gauche, le résultat de l'inférence du LLM (résumé, données structurées, réponse du chatbot…). À droite, le document source. Quand l'utilisateur clique sur un élément du résultat, le volet droit affiche automatiquement la page concernée avec le segment de texte pertinent surligné.
L'image en entête de l'article illustre cette interface utilisateur.
L'approche technique derrière l'extraction avec preuve visuelle
Ce que fournit l'OCR
Le système s'appuie sur AWS Textract comme moteur OCR (d'autres outils fournissent des métadonnées équivalentes). Pour chaque élément détecté, Textract renvoie un bloc contenant notamment le texte brut extrait (Text), la position sur la page sous forme de bounding box (BoundingBox), le type de bloc (PAGE, LINE, WORD, TABLE, CELL, IMAGE…) et les relations parent-enfant entre blocs (Relationships).
{
"BlockType": "LINE",
"Confidence": 97.36617279052734,
"Text": "MEUBLES à PIZZA",
"Geometry": {
"BoundingBox": {
"Width": 0.2342921942472458,
"Height": 0.02162465639412403,
"Left": 0.7166793942451477,
"Top": 0.028492335230112076
},
"Polygon": [
{ "X": 0.7167330980300903, "Y": 0.02968931570649147 },
{ "X": 0.9509715437889099, "Y": 0.028492335230112076 },
{ "X": 0.9509004354476929, "Y": 0.04892276972532272 },
{ "X": 0.7166793942451477, "Y": 0.05011698976159096 }
]
},
"Id": "63422f23-5ac4-4418-b002-9776ed79301b",
"Relationships": [
{
"Type": "CHILD",
"Ids": [
"9882688f-4d80-4835-87e2-3f1486295e1f",
"29ca488f-2fec-4464-9c7d-2c4b616e9a4d",
"f9c31d27-1fdc-460c-9fdd-5b8ee69d3e46"
]
}
]
}
Ce sont ces bounding boxes qui permettent de savoir quels pixels surligner, et la structure arborescente qui permet de contrôler le niveau de granularité de la preuve (mot, ligne, tableau…).
Le défi de prompt engineering : rester sobre en tokens
Dans une pipeline classique OCR + LLM, seul le texte brut est envoyé au modèle. Tout le reste des métadonnées sert uniquement au formatage (tableaux en markdown, par exemple). Envoyer l'intégralité du JSON Textract au LLM serait une approche naïve désastreuse : environ 100 000 tokens par page, contre 1 000 tokens pour le parsing classique.
L'astuce consiste à n'ajouter les métadonnées qu'à un niveau de granularité élevé. Concrètement, seuls les blocs de type ligne et tableau sont numérotés et balisés dans le prompt via des tags <LINE {id}> et <TABLE {id}>. Les blocs de granularité plus fine (mots, cellules) ne reçoivent pas de métadonnées explicites : le LLM peut les référencer via leur parent et leur valeur textuelle.
Ce choix de granularité n'est pas arbitraire. Étant donné la structure des blocs Textract, chaque preuve peut prendre quatre formes : un bloc de texte (environ un mot), une ligne, un tableau ou la cellule d'un tableau. Pour chaque tâche, le LLM peut remonter plusieurs preuves de natures différentes — par exemple une ligne et trois cellules de tableau.
Réconcilier la sortie du LLM avec les blocs OCR
Comme toutes les métadonnées ne sont pas incluses dans le prompt, le LLM peut référencer des blocs qui n'existent pas tels quels dans la sortie OCR. Exemple typique : l'OCR a extrait 6 x 7 comme trois blocs distincts (6, x, 7), mais le LLM les référence comme un bloc unique. Une étape déterministe de post-traitement résout ce décalage en identifiant, par similarité textuelle (fuzzratio), les blocs OCR dont la combinaison correspond au mieux à la référence du LLM.
La structure de réponse : dédoubler valeur et preuve
Pour que le système fonctionne, la réponse du LLM doit contenir à la fois le résultat et les métadonnées de localisation associées. En pratique, cela revient à utiliser les sorties structurées (JSON) en dédoublant chaque champ en une valeur et une preuve.
Au lieu d'une extraction classique :
{
"temperature": "4°C",
"power (kW)": 42,
"description": "SOME VERY LONG TEXT"
}
La réponse prend cette forme :
{
"temperature": {
"value": "4°C",
"proof": [{ "type": "WORD", "line": 2, "value": "4°C" }]
},
"power (kW)": {
"value": 42,
"proof": [{ "type": "WORD", "line": 5, "value": "6 x 7000 Watts" }]
},
"description": {
"value": "SOME VERY LONG TEXT",
"proof": [
{ "type": "LINE", "id": 19 },
{ "type": "LINE", "id": 20 }
]
}
}
L'affichage : annoter l'image source
Une fois les métadonnées de localisation retracées jusqu'aux blocs Textract, le système dispose des coordonnées (entre 0 et 1) des quatre coins de chaque bounding box sur le document.
Les images sont annotées par le backend. Le frontend a ainsi accès pour chaque donnée extraite à l'image annotée correspondante.
Côté technique, l'annotation des images repose sur la librairie sharp, et le traitement des PDFs sur pdf-lib.