Qu’est-ce que GraphQL ? Ou plutôt commençons par la question, qu’est-ce que n’est pas GraphQL ? Malgré son nom, GraphQL n’est pas une base de données alternative à MySQL ni un langage concurrent à SQL. En fait, GraphQL est un langage de requêtes pour API. Si on fait un bref historique des différentes façons d’envoyer et recevoir de la donnée au cours du temps, on peut distinguer trois phases : l’âge de pierre, l’âge du bronze et l’âge du fer.
Dans notre petite analogie, l’âge de pierre correspond au protocole SOAP. Concrètement, les API SOAP envoie des données sous format XML, généralement en utilisant le protocole HTTP (mais pas forcément). Le vrai problème avec SOAP, c’est l’aspect verbeux des requêtes; le format est lourd et inadapté pour les problématiques actuelles. Il a fallu trouver une solution en passant à l’âge de bronze, l’API REST. Pour le coup, REST n’est pas un protocole (contrairement à SOAP) mais plutôt un ensemble de règles et contraintes à utiliser pour établir un minimum de cohérence et inter-opérabilité sur internet. REST utilise exclusivement le protocole HTTP et généralement dialogue via un format JSON. Comme Monsieur Jourdain dans le Bourgeois gentilhomme qui faisait de la prose sans le savoir, beaucoup ont finalement fait du REST sans le savoir, en mettant en place un simple serveur Node.js par exemple. L’inconvénient principal de REST est aussi son principal avantage, sa malléabilité. Il n’y a pas vraiment de standard suivi par tous et ça peut vite se transformer en far west ! Nous avons donc dû évoluer vers l’âge du fer. L’âge du fer, c’est GraphQL.
On ne va pas passer trop de temps sur la théorie, mais c’est important de comprendre que contrairement aux autres, GraphQL est un langage; c’est une façon simple et élégante de faire des requêtes au serveur. GraphQL utilise la méthode POST du protocole HTTP et contrairement à REST, il n’utilise qu’une route unique. GraphQL n’a besoin que d’un endpoint. Pour mieux comprendre tout ça, nous allons faire un petit site avec REST d’une part et regarder comment on pourrait l’adapter avec GraphQL.
Notre site va s’intéresser au mystérieux peuple des Galadhrim, un peuple d’elfes du Seigneur des anneaux. Ce peuple vit dans la forêt et construit des cabanes dans les arbres pour maisons. Dans notre monde, chaque elfe pourra aussi avoir des amis et une maison. Si on veut construire une base de données à partir de ces informations, il nous faudrait :
elfes : elfeId (Int), name (String), age (Int), houseId (Int)
houses : houseId (Int), surface (float), woodType (enum)
friends : friendId (Int), firstElfeId (Int), secondElfeId (Int)
Voici à quoi doit ressembler notre page :
On peut distinguer 4 parties :
Mes informations personnelles
La surface de notre maison et le type de bois utilisé
La liste de mes amis
La liste des amis de mes amis
Avec REST
Techniquement, en utilisant une API REST, il nous faudrait faire les appels suivants :
GET /elfe pour récupérer les données de mon elfe
GET /house pour récupérer les données de ma maison
GET /friends pour récupérer l’ensemble de mes amis
GET /friends?elfeIds=[1,4,8] pour récupérer les amis de mes amis
Nous pourrions techniquement faire l’ensemble de ces requêtes d’un coup mais cela serait spécifique à cette page et toute notre API deviendrait du cas par cas. Ce qui n’est pas vraiment une bonne pratique car cela complexifie grandement la lisibilité du code et la compréhension de l’API pour un développeur, qui aurait affaire à une multitude d’endpoints spécifiques. Aussi, pour préserver l’architecture la plus épurée et simple, il est sans doute plus logique de faire 4 appels API consécutifs.
Avec GraphQL
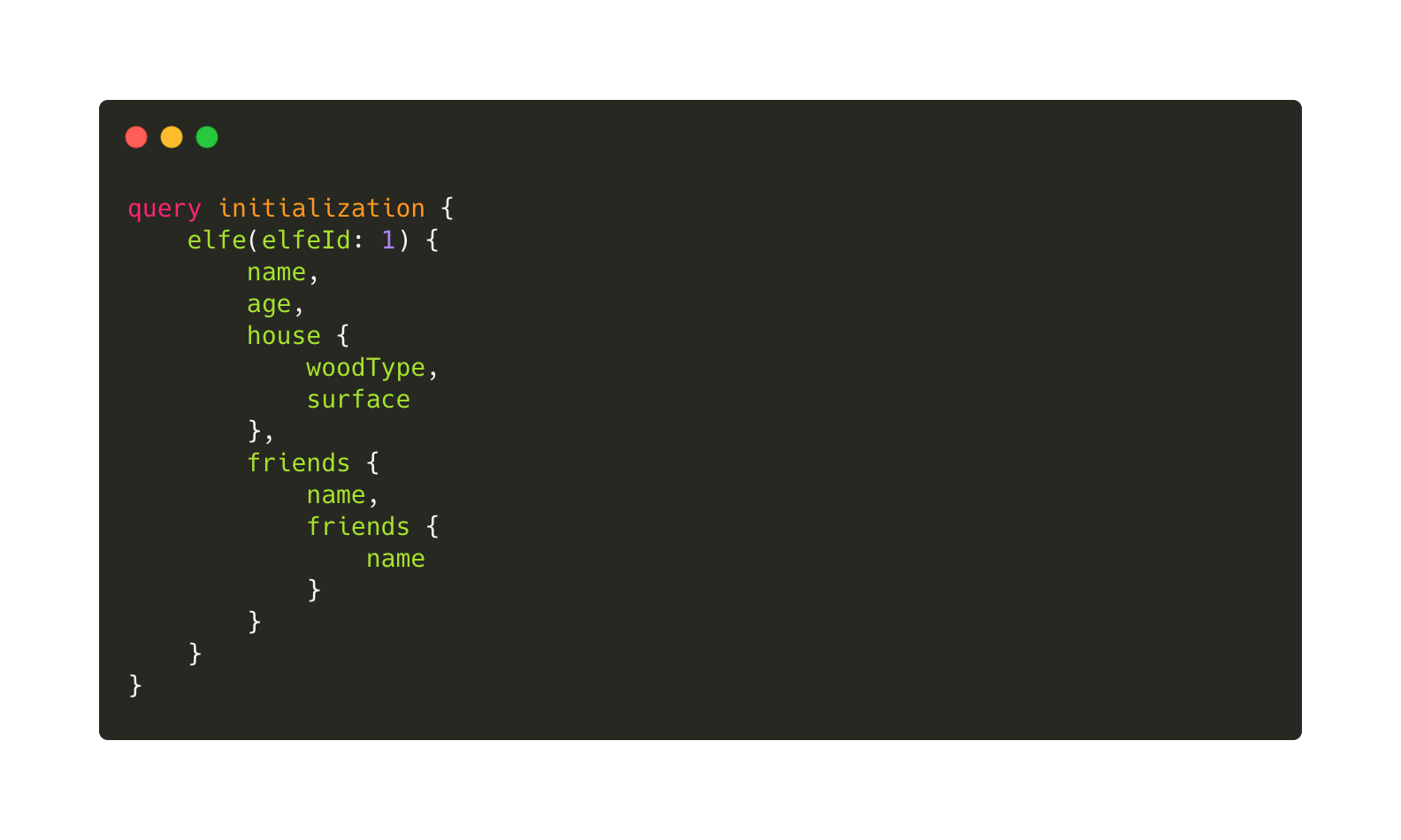
Avec GraphQL, il n’y a qu’un appel :
En effet, GraphQL est un langage et donc toute la subtilité réside dans le contenu (body) envoyé la requête. Ce contenu suit un format particulier et il est interprété par notre back-end. Voilà à quoi ressemble notre body :
Essayons de décortiquer le contenu :
Le mot query fait référence au type de requête qu’on fait à GraphQL; on en distingue deux, les types query et les types mutation. Une query demande des données au serveur, une mutation fait une modification, par exemple une insertion en base de données. Ici, on demande des informations, donc on fait une requête de type query. Il y a aussi un autre type, appelé subscription, mais nous ne l’utilisons pas ici.
Le mot initialization n’est pas très important, c’est le nom que j’ai donné à ma query; vous auriez pu mettre n’importe quoi, legolas par exemple, et ça aurait marché !
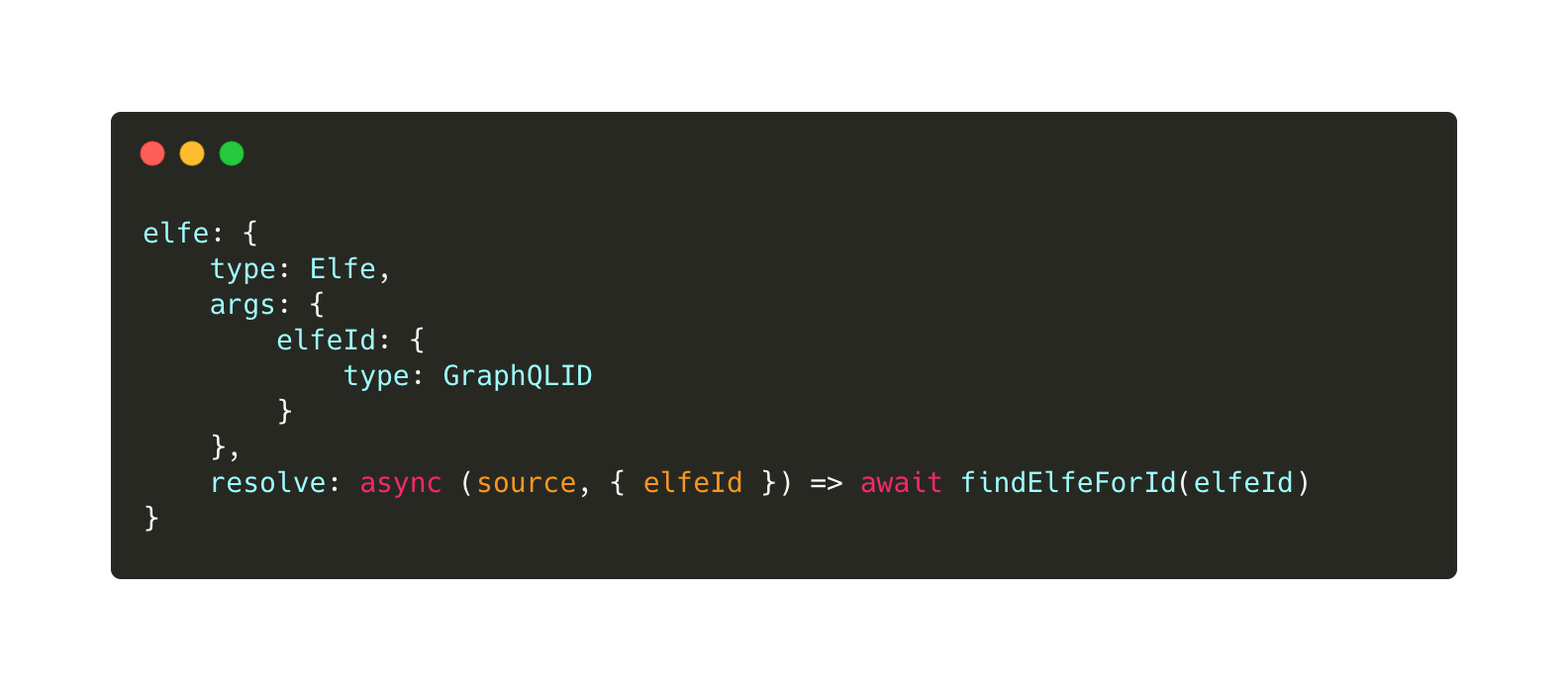
Le mot elfe par contre est important; il fait référence à la query que je vais utiliser. Je m’explique : lorsque je crée mon API GraphQL, je vais devoir lui écrire une représentation de ma base pour qu’il puisse comprendre les attributs de chacun, les liaisons, etc. Ma query va ressembler à ça :
On va donc lui demander de me renvoyer un elfe pour un identifiant elfeId passé en paramètre (dans notre cas, elfeId vaut 1). On utilise ensuite un resolver qui va aller me chercher mes informations. Pour faire simple, un resolver, c’est une fonction qui va chercher des données en base via une requête SQL par exemple.
Le type Elfe que l’on définit dans notre query possède donc tous les attributs dont on a besoin : un nom, un âge, une maison et des amis. Le resolver getElfeForId va donc utiliser lui-même d’autres fonctions pour aller chercher dans la base de données ce qu’il nous faut.
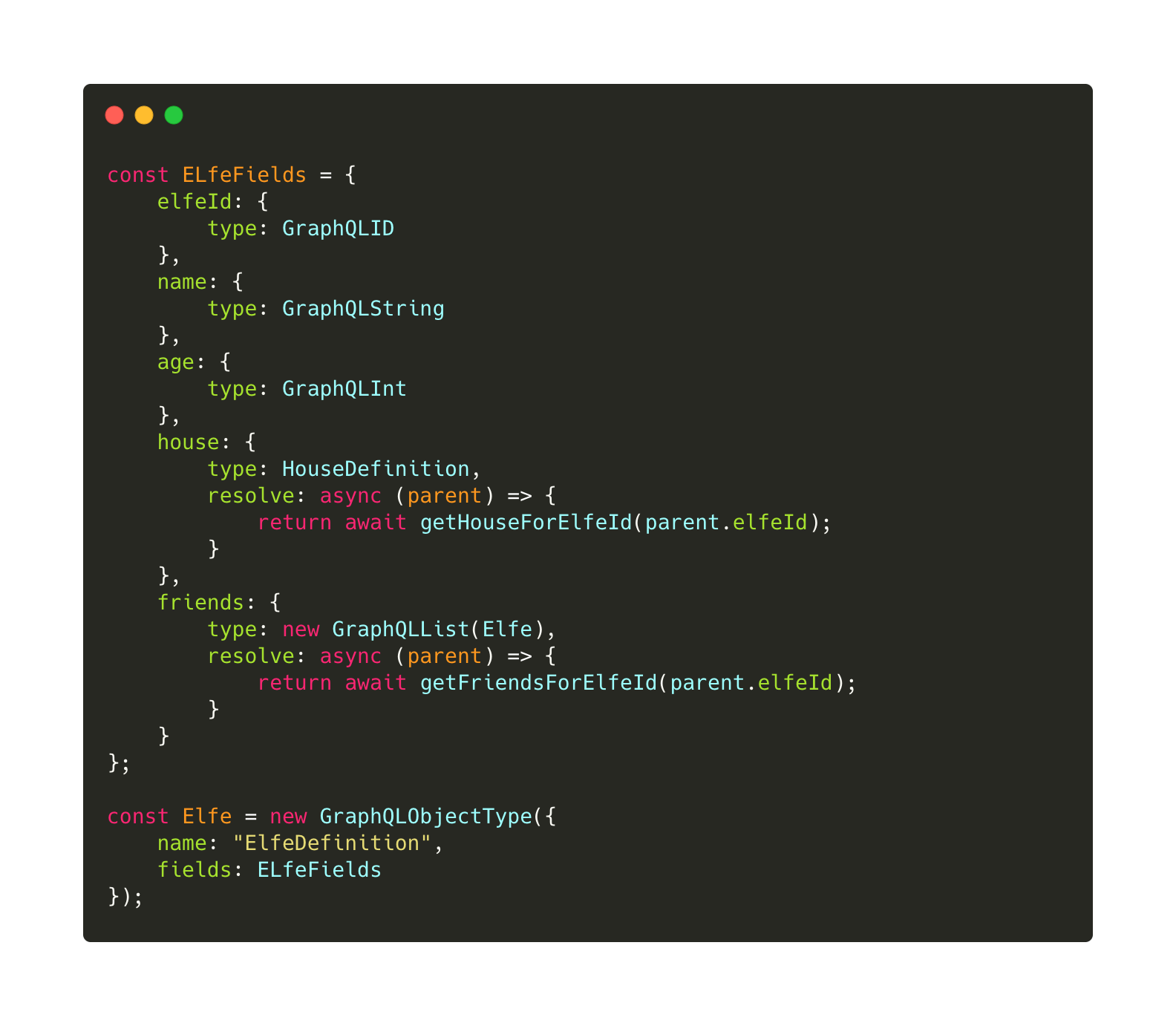
Le type Elfe dont nous parlons est défini comme cela au niveau du back-end :
Il est important de comprendre ici qu’il n’y a pas de magie à ce niveau là, il faut explicitement faire des requêtes SQL pour ensuite produire l’objet Elfe que nous attendons. Ainsi, les fonctions getHouseForElfeId et getFriendsForElfeId sont au final des requêtes SQL. Dans GraphQL, les champs (fields) ont des types; ces types peuvent être primitifs comme des entiers (GraphQLInt) ou des types générés comme le type Elfe. Ainsi, on peut renvoyer un objet ou une liste d’objets (en utilisant GraphQLList) en tant que champ. Aussi, avec la définition de l’objet Elfe que l’on fait ci-dessus, le champ friends s’attend à renvoyer une liste d’elfes !
Il y a donc beaucoup de travail à faire en amont mais une fois qu’il est fait, il n’y a plus à toucher au back-end, plus de nouvelles routes à faire, etc. ! Tout se passe ensuite avec le front, qui peut demander à notre API ce dont elle a besoin. Si dans une page nous n’avons besoin que du nom de l’elfe par exemple, notre requête ressemblera à ça :
Aucun travail n’est à faire en back-end, tout est déjà prêt. On peut donc faire une liste de courses de tout ce dont on a besoin au bon moment !
Voilà l’essence de GraphQL en quelques lignes. Il est important de souligner que GraphQL apporte une norme et une facilité d’utilisation non négligeables. Outre l’aspect pratique, la gestion d’erreur de GraphQL rend son implémentation simple, si quelque chose ne va pas, GraphQL nous le dira rapidement ! Certains se demanderont peut-être comment gérer les droits de lecture et d’édition, pour cela il faudra utiliser la notion de context ! De nombreux aspects de GraphQL peuvent être approfondis (et le seront peut-être dans un futur article ?) mais l’idée de cet article est de présenter le besoin et la réponse offerte par GraphQL.