2016 - AlphaGo versus Lee Sedol - quand l’IA devient créative ?
Le 15 mars 2016, le cinquième match de Go entre Lee Sedol, 2e joueur le plus titré de l’histoire, et
AlphaGo, un programme informatique développé par Deepmind, une entreprise britannique rachetée par Google deux ans plus tôt, prenait fin. AlphaGo remportait la compétition, avec 4 victoires pour 1 défaite.
En parlant du coup 37 de la deuxième partie, Sedol déclara : “Je pensais qu’AlphaGo était basé sur des calculs de probabilité, et que ce n’était qu’une simple machine. Mais, quand j’ai vu ce coup, j’ai changé d’avis. Assurément, AlphaGo est créatif. Ce coup était vraiment créatif et beau.”
Le jeu de Go a longtemps été considéré comme un challenge de taille pour l’IA : le jeu présente 10 puissance 170 configurations de plateau possibles, soit 1 googol (10 puissance 100) fois plus que le jeu d’échecs. C’est même plus que le
nombre d’atomes dans l’univers connu.
AlphaGo est un système IA combinant deux réseaux de neurones (Policy Network et Value Network) et algorithmes de recherche avancés. L’entraînement d’AlphaGo a tiré profit du Reinforcement Learning : AlphaGo a joué des millions de parties contre lui même.
Malgré sa complexité mathématique astronomique, le jeu de Go consiste “simplement” en un plateau de 19x19 cases, et de 361 pions. Cet univers fini semble, intuitivement, plus simple a maîtriser pour une machine que de se déplacer dans et agir sur l’univers physique (robotique), ou... les mathématiques, dont Banach disait qu’elles restent “la plus belle et la plus puissante création de l’esprit humain”. Jusqu’à maintenant ? C’est ce que nous allons tenter de découvrir.
Le benchmark MATH
Les problèmes de MATH couvrent 7 sujets, dont la géométrie, l’algèbre linéaire et la théorie des nombres, et sont classés en 5 niveaux de difficulté. La performance humaine sur MATH n’est pas parfaite : un doctorant en informatique aurait une performance d’environ 40%, alors qu’un triple médaillé d’or aux Olympiades Internationales de Mathématiques aurait une performance d’environ 90%.
Et les modèles d’IA ? Leur performance varie de 3.0% à 6.9%, avec un maximum à 15% sur les problèmes les plus simples. Les modèles testés étaient GPT-2 (de 100 millions de paramètres à 1.5 milliards) et GPT-3 (de de 13 à 175 milliards de paramètres), modèles aujourd’hui dépassés.
En 2021, les auteurs concluaient que, contrairement à de nombreuses autres tâches basées sur du texte, “scaler” des transformer-based models (qui sont le
fondement de l’IA Générative) ne permettent pas de résoudre le benchmark MATH.
Et aujourd’hui ?
Les modèles “o” d’OpenAI et le benchmark AIME
Moins de 4 ans plus tard, la situation est quelque peu différente : le
modèle o1 d’OpenAI, publié en septembre 2024, atteindrait sur le benchmark MATH une performance de 94.8%. Ce benchmark est donc maintenant considéré comme saturé. o1 obtient par ailleurs une performance de 83.3% sur les problèmes de la compétition AIME 2024, un benchmark d’une difficulté supérieure.
AIME (pour American Invitational Mathematics Examination) est un dataset comprenant les problèmes de la compétition du même nom, ayant cours depuis 1983. C’est un examen de 3 heures comprenant 15 questions, destiné aux meilleurs lycéens américains en mathématiques. Les problèmes associés sont complexes, exigent des approches créatives, et ont tous pour solution un entier compris entre 0 et 999.
Les modèles d’OpenAI de la famille “o” sont les premiers de leur catégorie, avec un scaling sur le test-time compute. Le scaling at test-time signifie, si l’on raisonne de manière anthropomorphique, que le modèle prend le temps de réfléchir avant de donner une réponse. Plus concrètement, il génère des tokens cachés, où il développe de longs raisonnements, avant de générer la réponse définitive qui sera fournie à l’utilisateur. Cette innovation permet donc aux modèles d’être considérés comme des
systèmes pensants de type II, et non de type I.
Encore plus récemment, le 31 janvier 2025, OpenAI a publié deux nouveaux modèles : o3 et o3-mini. o3-mini aurait une performance de 80% sur AIME 2025, et o3 aurait une performance de 96.7%, saturant donc ce benchmark !
Le “scaling at test-time” est une nouvelle dimension de recherche prometteuse, et devrait permettre, dès 2025 et au-delà, de développer des modèles d’IA aux raisonnements de plus en plus robustes et complexes. Encore faudrait-il, pour attester de cela, que de nouveaux benchmarks plus exigeants soient créés. C’est le cas depuis quelques mois, avec FrontierMath.
FrontierMATH
En novembre 2024, l’institut de recherche Epoch AI publiait
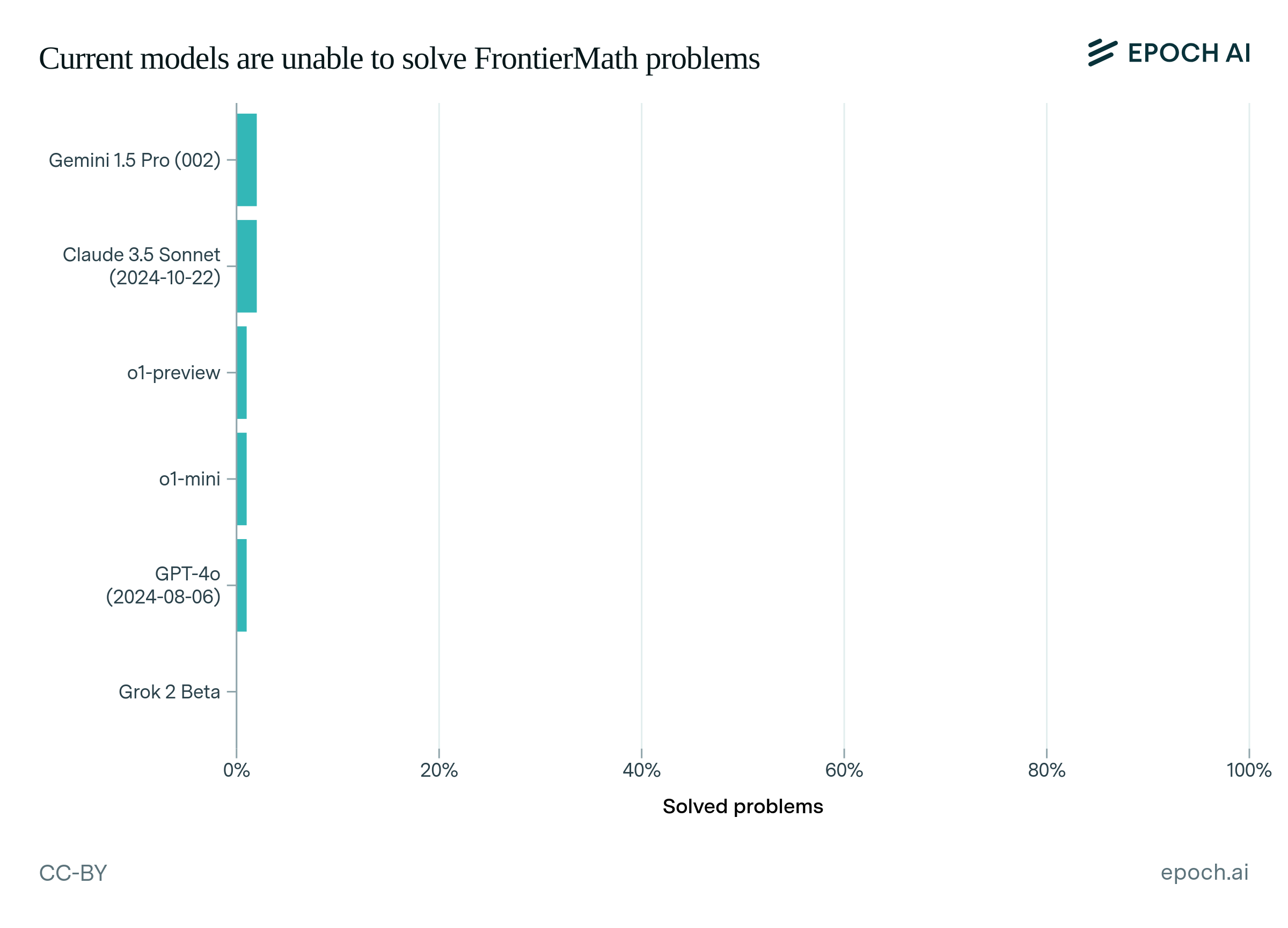
FrontierMath, un benchmark contenant des centaines de problèmes experts, que les meilleurs modèles d’IA (de l’époque) ne résolvent que dans 2% des cas.
Ces problèmes ont été rédigés par une soixantaine de mathématiciens, incluant des rédacteurs de questions d’Olympiades et des médaillés Fields. Volontairement novateurs et non-publiés, ces problèmes visent à tester la compréhension mathématique réelle des modèles. Ils sont aussi “robustes”, avec une probabilité inférieure à 1% de deviner au hasard la réponse correcte.
Selon Epoch AI, les modèles ont été testés dans les conditions les plus favorables possibles : un temps de réflexion étendu, et la possibilité d’expérimenter et d’itérer via un environnement Python où ils peuvent exécuter du code pour tester des hypothèses et vérifier leurs résultats intermédiaires. En novembre 2024, seuls Gemini 1.5 Pro et Claude 3.5 Sonnet résolvaient plus de 1% des problèmes. En mathématiques, victoire pour les (meilleurs) humains, donc ?
A date, oui. Toutefois, le modèle o3 d’OpenAI, publié peu de temps après ce benchmark, obtiendrait une
performance de 25%, indiquant un progrès fulgurant en quelques mois.
D’après cette
source, FrontierMath se décomposerait en trois niveaux de problèmes, le Tier 1 correspondant en difficulté aux Olympiades Internationales de mathématiques. o3 serait donc capable de résoudre la majorité des problèmes de niveau, mais pas au-delà.
Et DeepMind ? AlphaGeometry et AlphaProof
Mais revenons à DeepMind, aujourd’hui une filiale et un laboratoire de recherche de Google. Moins médiatisés qu’OpenAI, ces derniers ne sont pas en reste dans cette course à l’innovation. En juillet 2024, ils publiaient les modèles
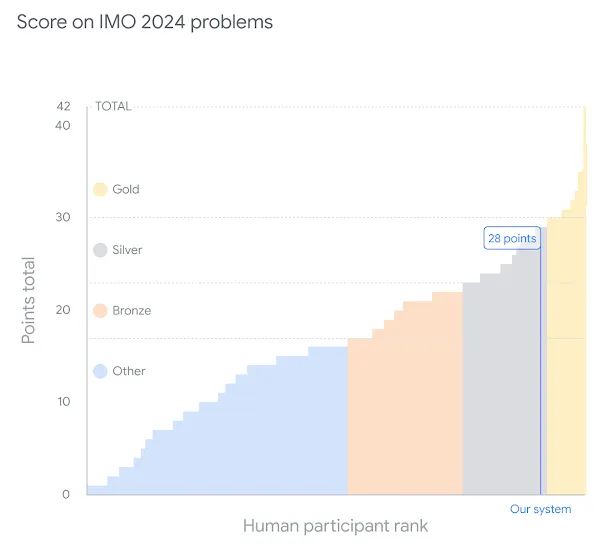
AlphaProof et AlphaGeometry 2, dédiés au raisonnement mathématique formel et basés sur du Reinforcement Learning. Ces modèles ont résolu 4 des 6 problèmes de l’édition 2024 des Olympiades Internationales de mathématiques, une performance permettant d’obtenir une médaille d’argent sur cette édition. L’équivalent d’une 59e place sur 609 participants.
Enfin, DeepMind déclare avoir testé, sur cette édition, une système de raisonnement en language naturel, basé sur Gemini, et permettant de ne pas avoir à traduire les problèmes présentés dans le langage formel propre à AlphaProof et AlphaGeometry 2. Les résultats seraient “très prometteurs”. L’édition 2025 des Olympiades devrait réserver son lot de surprises.
Et à l’avenir ?
Concernant les benchmarks, des innovations sont aussi à attendre : Epoch AI a récemment annoncé travailler sur une
suite de problèmes de Tier 4, problèmes qui devraient exiger la collaboration de départements de mathématiques entiers pour être résolus.
Les plus optimistes sur l'avenir de l'IA soutiennent qu’augmenter le volume de données d’entrainement et la puissance de calcul fournie, permettront d’augmenter de manière logarithmique (et indéfinie) les performances des modèles d’IA, selon les
scaling laws. Ce scaling peut se faire sur plusieurs dimensions différentes, comme vu précédemment : le pre-training, le post-training, et, plus récemment, sur les “computations at inference time”.
En décembre 2024, OpenAI a invité Terence Tao, médaillé Fields 2006, à une
conférence sur le futur des mathématiques avec les modèles “à raisonnement”. Ce dernier est optimiste sur l’utilisation de l’IA en général sur la recherche en mathématiques, où les modèles joueront le rôle d’assistants de recherche, capables de réaliser une partie des tâches aujourd’hui entièrement manuelles.
Toutefois, ce dernier avance que les mathématiques ne seront jamais entièrement résolues par l’IA : "Même si l’IA devient capable de faire toutes les mathématiques que nous faisons aujourd’hui, cela signifie que nous passerons simplement à un type supérieur de mathématiques”. Une chose est sûre, l’IA a un rôle important à jouer, et permettra d’accélérer le rythme des découvertes dans ce domaine.