Lors du développement d'une application, il y a toujours une petite appréhension lors la mise en production. Cette petite voix qui vous dit "est-ce que mon code ne va rien casser ?" ou encore "est-ce que je suis sûr d'avoir passé tous les tests avant de push ?". Cette crainte est d'autant plus justifiée quand vous arrivez sur un projet existant et que vous n'avez pas encore une connaissance globale de ce dernier.
Pire encore quand vous êtes développeur sur ce projet et qu'un nouveau arrive, on n'est pas plus rassuré. On a beau avoir défini des tests,
rien ne nous assure que les développeurs les lancent avant la mise en production. C'est ici que les rôles de
l'intégration continue (
CI) et du développement continu (
CD) prennent tout leur sens.
GitLab CI/CD est une fonctionnalité de GitLab qui permet de mettre en place des pipelines de CI/CD pour n'importe quel projet, qu'il soit nouveau ou existant, pourvu qu'il utilise Git.
Motivations
Pour qui ?
Vous pouvez utiliser GitLab CI/CD même sans héberger votre projet sur GitLab, en choisissant l'option "Run CI/CD for external repository". Si vous utilisez GitHub, vous pourrez ainsi voir le statut de votre pipeline après avoir push un commit :
Pourquoi ?
Mettre en place la CI/CD avec GitLab vous permet d'automatiser les étapes :
d'intégration continue : Build > Tests (unitaires, d'intégration, de non-régression...)
de déploiement continu : Review > Déploiement (staging, production...)
Cette automatisation accélère la production de code : un seul commit suffit à déclencher une pipeline côté GitLab qui s'occupera de générer un build de production, lancer la suite de tests et déployer la nouvelle version en staging/production ! Cela permet également d'augmenter la confiance des développeurs et la qualité du code envoyé en production, car on a l'assurance que chaque modification est passée par ce processus.
Mise en place
Les stages
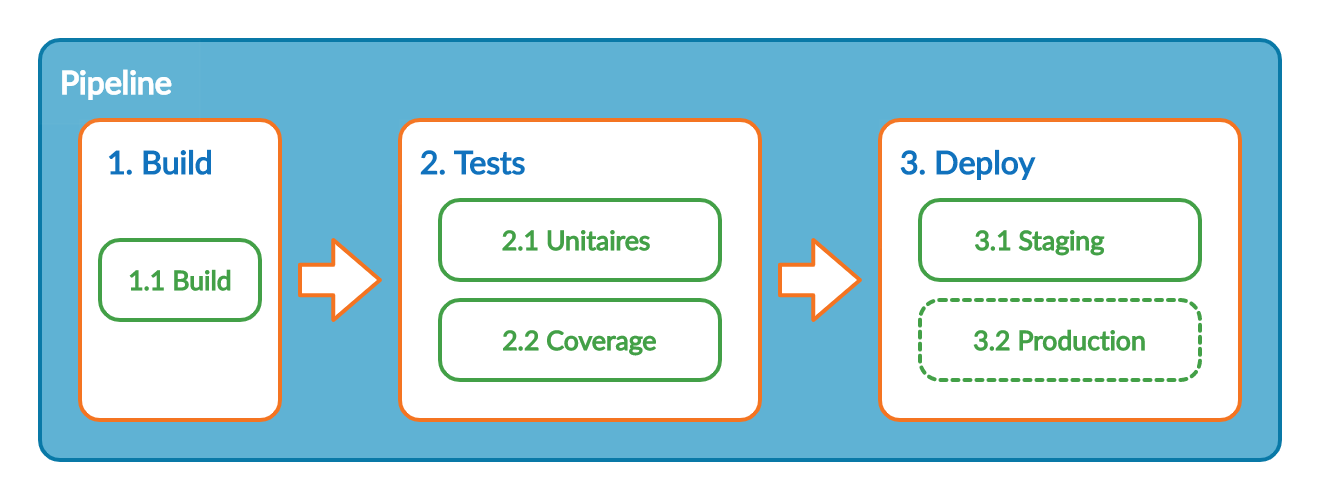
Nous allons analyser le cas pratique de la mise en place d'une pipeline de CI/CD pour une application web écrite en JavaScript et utilisant Next.js. Dans un premier temps, il faut définir les différents stages de la pipeline de CI/CD que l'on souhaite créer. Je vous propose un découpage en trois stages : Build, Tests et Deploy.
Ces stages sont lancés séquentiellement et sont composées de jobs. Une étape doit contenir au moins un job, ces derniers étant exécutés en parallèle par défaut. Voici la structure de la pipeline que nous allons mettre en place, libre à vous de l'adapter :
On y retrouve nos trois stages : Build, Tests et Deploy. Sur ce schéma, les stages Tests et Deploy possèdent chacun deux jobs.
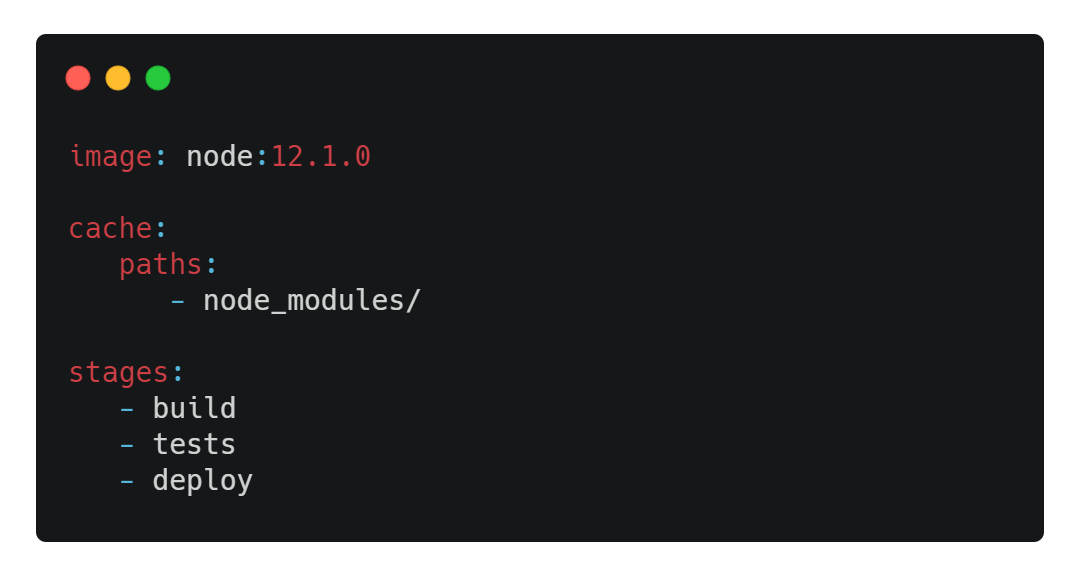
Pour décrire l'architecture de notre pipeline à GitLab, nous allons devoir créer un fichier .gitlab-ci.yml à la racine de notre projet et y ajouter ces lignes :
Voyons ici plus en détail le contenu de notre fichier :
image vous permet de spécifier l'image Docker à utiliser pour lancer votre pipeline, bien entendu à adapter selon vos besoins,
cache nous permet ici de garder en cache nos node_modules pour éviter d'avoir à les re-télécharger à chaque fois,
Enfin,
stages nous permet de définir nos différentes étapes au sein de la pipeline.
Les jobs
Bien, les stages ont été définis, mais comme je l'ai mentionné précédemment, un stage doit contenir au moins un job, autrement notre pipeline n'exécute rien et n'a pas d'intérêt. Voyons donc comment définir notre premier job, build, en rajoutant ces lignes à la suite de notre .gitlab-ci.yml :
Ici, le nom de notre job est
build, et il se situe au sein du stage
build. La partie
script définit
ma procédure de build pour mon projet utilisant Next.js et génère à l'issue de la commande
next export un dossier
out contenant mes fichiers générés.
L'utilisation du mot-clé artifacts ici me permet de définir des fichiers et/ou dossiers qui vont être stockés au sein de cette pipeline pour être éventuellement passés à d'autres jobs plus tard. Dans notre cas, nous spécifions le dossier out qui contient nos fichiers générés pour les passer plus tard au job deploy.
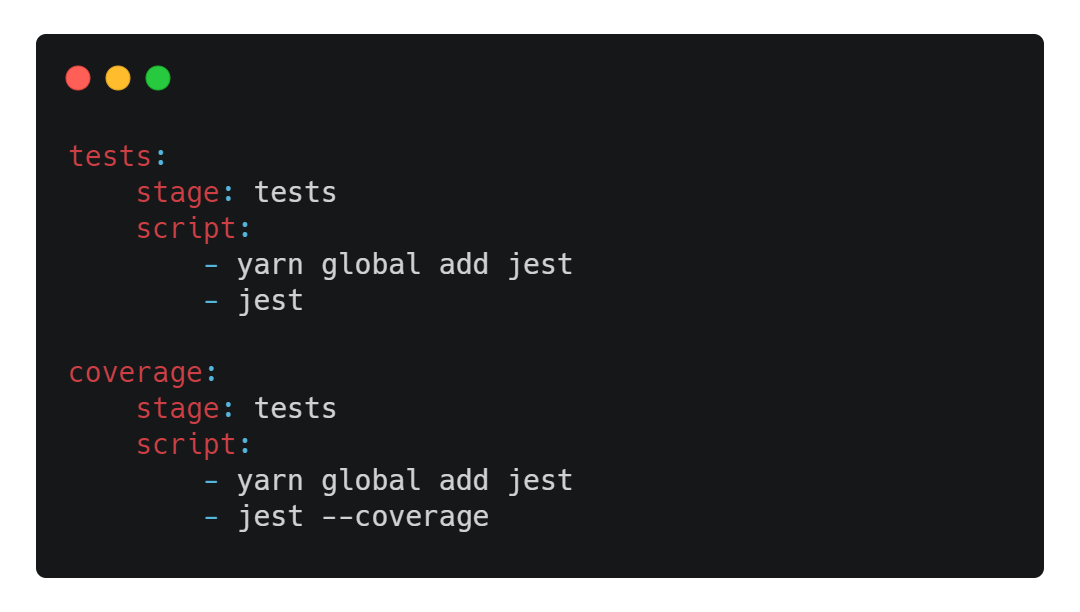
Nous pouvons maintenant ajouter les jobs correspondants au stage de tests. Ajoutez ces lignes à la suite de votre .gitlab-ci.yml :
L'ajout de plusieurs jobs à un stage se fait sans difficultés, on définit simplement pour chaque job le stage auquel il appartient, ici tests. Les runners de GitLab utilisent notre image Docker node:12.1.0 qui ne contient pas Jest par défaut : on ajoute donc la dépendance requise avant de lancer les commandes dont on a besoin.
Ces deux jobs se lanceront en parallèle l'un de l'autre, dès lors que l'étape précédant tests sera terminée. Nous pouvons passer à la dernière étape : le déploiement.
L'environnement
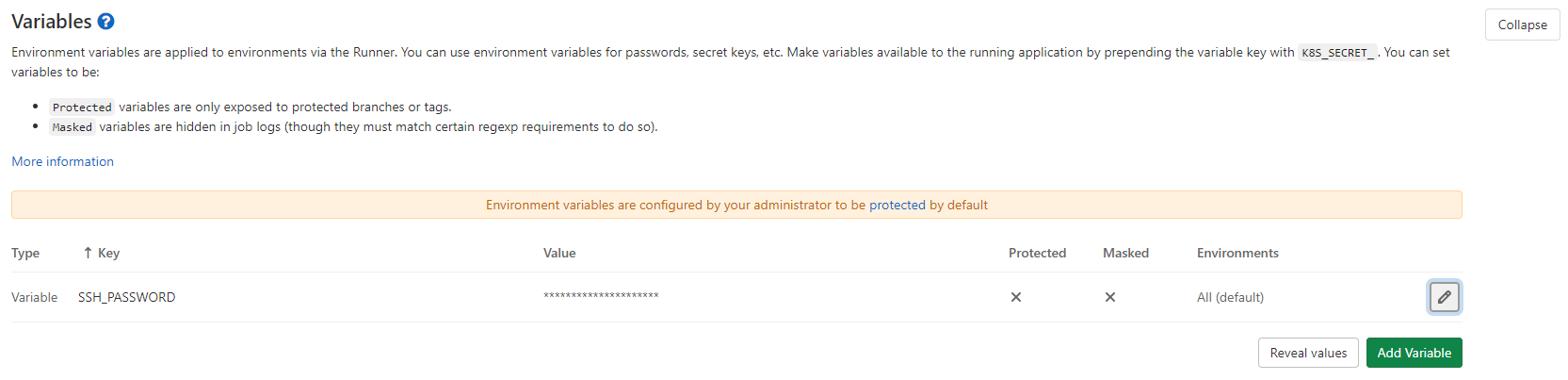
Dans cet article, j'ai choisi d'opter pour un déploiement en utilisant SSH, vous pouvez évidemment adapter les commandes si vous utilisez d'autres services comme AWS S3 ou GCP. GitLab offre la possibilité d'utiliser des variables d'environnement pour éviter d'écrire les identifiants de connexion au service de déploiement directement dans le fichier .gitlab-ci.yml.
Pour définir des variables d'environnement, rendez-vous sur l'interface GitLab et allez dans Settings > CI / CD > Variables. J'ai ajouté une variable USER_PASSWORD correspondant au mot de passe de ma connexion SSH.
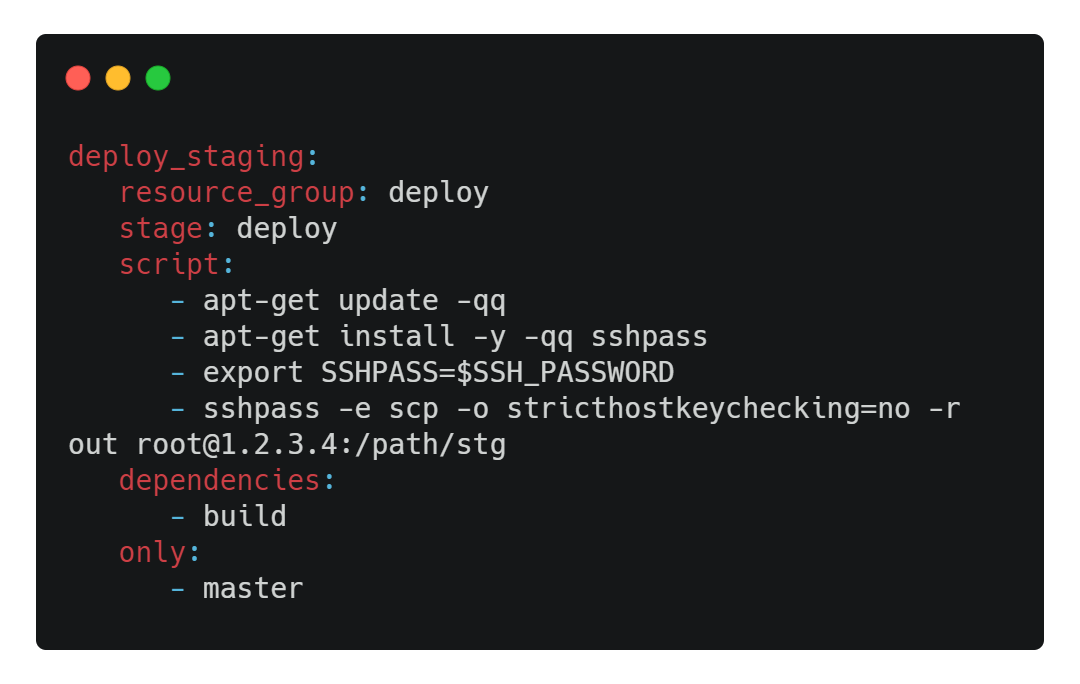
Nous pouvons désormais écrire nos deux derniers jobs, permettant de déployer le site en staging et en production ! Je vous propose de voir le job de staging en premier lieu :
Plusieurs points à voir ici. Premièrement, un resource_group valant deploy a été défini pour le job. Pour faire simple, il n'est pas possible pour les runners de GitLab qui exécutent nos pipelines de lancer deux jobs appartenant au même resource_group en parallèle, même si ces jobs se trouvent dans deux pipelines différentes en cours. On souhaite ici empêcher plusieurs déploiements vers notre serveur pour n'avoir qu'une connexion à la fois qui envoie des fichiers.
Le mot-clé dependencies spécifie le ou les jobs dont on souhaite récupérer les artifacts. Nous avons fait en sorte que notre job build envoie le dossier out comme artifacts, ce dernier va donc être récupéré par le job deploy_staging.
Finalement, le mot-clé only permet de spécifier depuis quelles branches le job peut s'exécuter un job. Ici, j'ai choisi de restreindre les déploiements depuis la branche master.
Nous sommes cependant en droit de nous poser une question : quelle est différence entre notre job deploy_staging et notre job deploy_production ? Après tout, deploy_production serait identique, à l'exception de la commande de déploiement.
Les templates
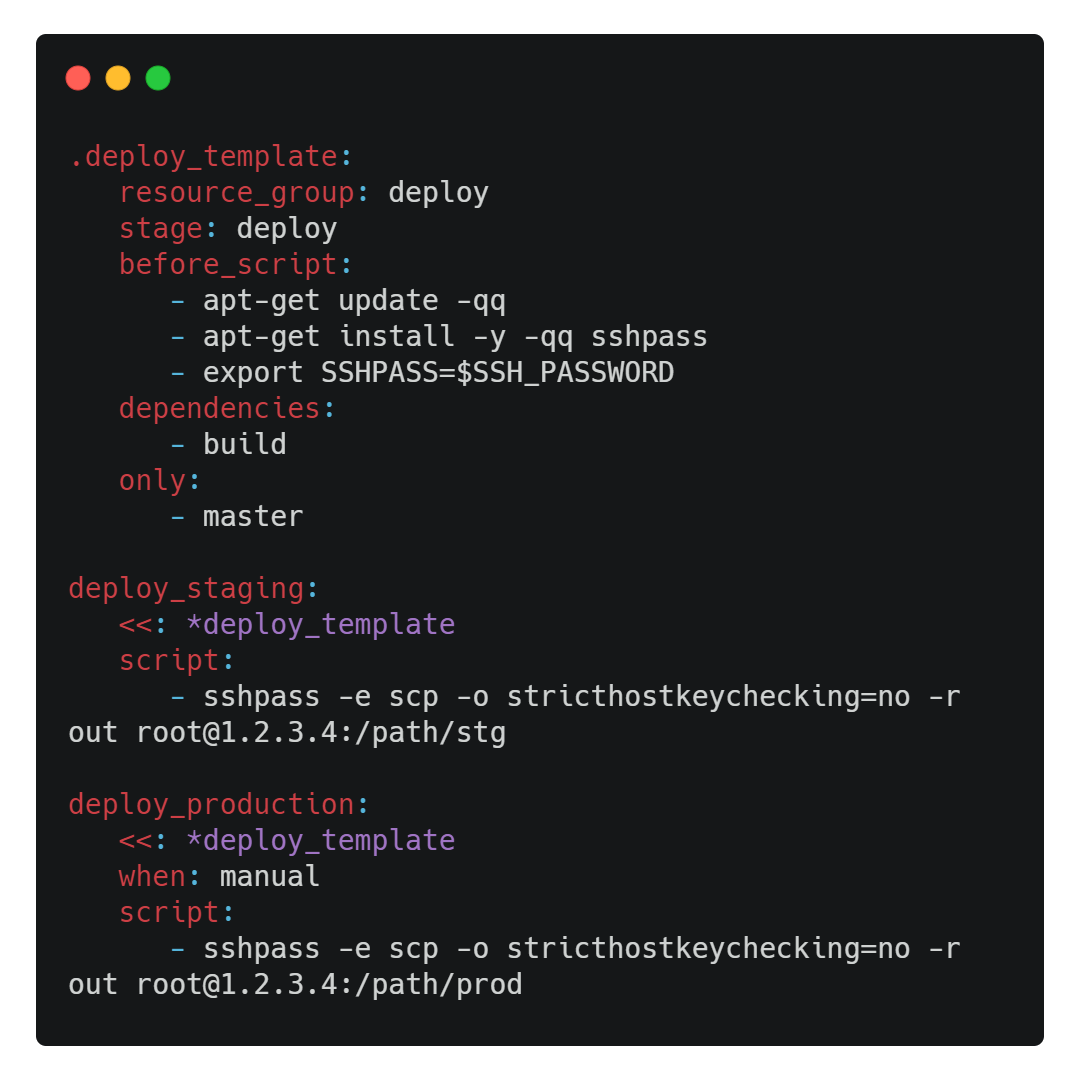
GitLab a mis en place un système de templates permettant la réutilisation du code, respectant ainsi les
principes de développement DRY. Dans notre cas, la quasi-totalité du code du job deploy_staging peut être réutilisée pour deploy_production. Je vous propose donc de modifier notre .gitlab-ci.yml pour définir ces deux jobs comme suit :
Nous définissions ainsi un template en commençant son nom par un point. Pour référencer le template, il suffit alors de l'inclure avec le mot-clé <<: et de référencer son nom avec une étoile *. Une petite subtilité ici : on ne veut pas que le contenu du script définie dans les jobs deploy_staging et deploy_production écrase le script du template. GitLab permet de définir notamment trois mots-clés : before_script, script et after_script. J'ai donc choisi de placer les commandes du template dans before_script pour qu'elles soient exécutées avant la commande de transfert de fichiers en SSH.
J'ai de plus ajouté pour le déploiement en production l'instruction when: manual. Cette dernière dit à GitLab que le job ne pourra s'exécuter que via un déclenchement manuel (et seulement si les jobs d'avant sont passés !).
Résultats
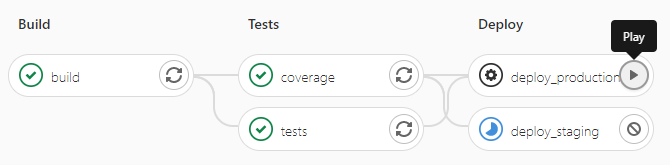
Voilà à quoi ressemble notre pipeline finale vue depuis l'interface de GitLab. On voit bien nos 3 stages et leurs jobs associés, ainsi que le job deploy_production qui ne peut être déployé que manuellement.
Si vous souhaitez être notifié sur Slack, Discord ou autre application du statut de vos pipelines lors d'un push, vous pouvez vous rendre sur GitLab et naviguer dans Settings > Integrations et activer les notifications correspondantes.
Conclusion
Vous connaissez désormais les bases de la mise en place d'une pipeline de CI/CD avec GitLab ! Bien entendu, il va sans dire que l'intérêt de cette démarche est moindre si vous n'écrivez pas de tests pour vos applications.
Écrivez des tests et profitez des avantages des services de GitLab pour améliorer votre flow de développement et augmenter votre productivité !
Cette brève introduction à GitLab ne se veut pas exhaustive, et si vous souhaitez aller plus au cœur des choses, je ne peux que vous recommander de lire
l'excellente documentation de GitLab CI/CD et de faire des tests de votre côté !